


Prima di scrivere questo articolo, che sintetizza il lavoro pubblicato sulla piattaforma www.iolavoro.info, mi sono chiesto a lungo se fosse o meno opportuno utilizzare le parole big data, per trattare un fenomeno che, per essere descritto, necessita di una grande quantità di dati. Poiché in questo momento si parla di big data anche quando si tratta di scrivere una lista della spesa un po’ più lunga del solito, ho deciso di fare una captatio benevolentiae, ben sapendo che i big data “veri” sono un’altra cosa rispetto al fenomeno di cui parlerò. La parola grande, o piccolo, e in questo la mia formazione da fisico non aiuta a prendere la questione alla leggera, non ha nessun significato se non viene specificato “rispetto a cosa”. Una formica è piccola rispetto a un elefante, ma è grande rispetto a un virus. Per questo, la notazione scientifica contempla gli ordini di grandezza, che consentono di avere un’idea esatta della “grandezza” fisica in esame. Così, se si parla di un oggetto che ha le dimensioni di 10^-9 metri si può fare un paragone con la grandezza di un atomo, mentre se si trattano distanze dell’ordine di 10¹¹ metri si può immaginare lo spazio che separa la terra dal sole. Per i dati non esiste un vero e proprio ordine di grandezza, che consenta di sapere quando “rientrano nella normalità” e quando sono “big”. In poche parole, non esiste un “rispetto a cosa”, o un riferimento certo e duraturo con cui effettuare dei confronti. Per questo, troppo spesso le parole big data, che hanno sicuramente un certo appeal sulle masse, si usano impropriamente e capziosamente (come nell’articolo che state leggendo). La mia idea è che i dati diventano big quando la loro raccolta e la loro elaborazione richiede risorse molto onerose, rispetto a quelle disponibili in un preciso momento storico, in termini di infrastrutture, strumenti, metodi e capacità di calcolo, per gestirne la quantità e la velocità di aggiornamento. Di conseguenza, le risorse richieste si possono considerare con buona approssimazione dei buoni indicatori di quanto i dati siano big. Negli anni ’80, raccogliere ed elaborare un dataset giornaliero contenente 100.000 record che occupasse uno spazio di 50 Mb era un’attività onerosa e in effetti, per le conoscenze e la tecnologia di quegli anni (i primi hard disk avevano una capienza di 5Mb), la parola big avrebbe potuto avere un senso. In un periodo in cui la quantità di dati è impressionante, penso all’IOT, alla telefonia, alle preferenze degli utenti raccolte dai colossi del web, il mercato del lavoro è interessato da un cambiamento, che, a dire la verità, è iniziato quando sono state introdotte le comunicazioni obbligatorie (CO), ovvero le comunicazioni telematiche attraverso le quali i datori di lavoro (pubblici e privati) segnalano le attivazioni, le cessazioni e le trasformazioni contrattuali al Ministero del Lavoro e alle regioni.
Si tratta di flussi di dati continui e consistenti che vengono raccolti attraverso un’infrastruttura costruita ormai più di dieci anni fa, quando le CO rientravano a pieno titolo tra i big data. Nel frattempo, il mondo si è trasformato: sono nati i servizi in cloud, i social network, Google e Amazon hanno cambiato l’economia e il modo di relazionarsi attraverso l’analisi di quantità di dati talmente consistenti e mutevoli da renderne difficile la quantificazione. Usare i big data per produrre statistiche ufficiali non è semplice: occorrono metodologie robuste, che non contemplino l’approccio classico di conduzione delle indagini (disegno del campione, raccolta dati, strutturazione e analisi dei dati, etc) o di trattazione degli archivi amministrativi. Le istituzioni che si occupano di statistiche ufficiali di solito non forniscono i dati di flusso, ma producono dati strutturati, sicuramente di qualità, che subiscono un processo di analisi e validazione affinché possano diventare “conoscenza”. Lo scotto da pagare per ottenere dati di qualità riguarda essenzialmente i tempi necessari al processo di analisi e diffusione I flussi di dati raccolti devono consolidarsi per diventare uno stock riferito a un arco temporale ben definito, che nella maggior parte dei casi descrive un fenomeno relativo a un arco temporale distante nel tempo. Si tratta di un limite che, oltre a far riflettere su come si sarebbe dovuto evolvere il ruolo delle istituzioni rispetto all’open data e alla fornitura dei dati di flusso, non consente di monitorare l’andamento dei fenomeni in tempo reale. I dati di flusso riguardanti il mercato del lavoro si possono suddividere essenzialmente in tre categorie:
- Comunicazioni obbligatorie: vengono raccolte dal Ministero del Lavoro, contengono dati personali, che per essere rilasciati dovrebbero essere resi anonimi, e non sono disponibili in formato open né sotto forma di stock né tantomeno sotto forma di flussi.
- Offerta di lavoro pubblico e privato: è presente sul web, in modalità totalmente destrutturata e localizzata su numerose piattaforme di settore.
- Curriculum vitae: sono contenuti perlopiù all’interno delle piattaforme che si occupano dell’erogazione di servizi associati al lavoro (incontro domanda offerta)
La disponibilità di queste “nuove” fonti dati è figlia del cambiamento sociale avvenuto negli ultimi anni: il “modo” di cercare lavoro è totalmente cambiato rispetto al passato. Gli annunci si consultano online, i cv si mettono in vetrina sui social network, le aziende affidano la ricerca di lavoratori qualificati ai cacciatori di teste e inseriscono le opportunità lavorative nei siti in cui si tenta di incrociare la domanda e l’offerta. In questo sistema, più o meno chiuso rispetto alle policy di diffusione adottate dalle diverse piattaforme, il linguaggio con cui si parla di professioni è totalmente destrutturato ed è subordinato alle mode e alla creatività delle aziende e dei lavoratori, che spesso inventano nuovi nomi per dare una diversa dignità a professioni che in realtà non hanno nulla di nuovo. Le istituzioni e il mondo della ricerca, invece, utilizzano dei sistemi classificatori attraverso i quali raccolgono i dati, li standardizzano e li analizzano. In Europa, per trattare i dati sulle professioni, esiste la ISCO (International Standard Classification of Occupations), il sistema classificatorio fornito dall,ILO (International Labour Organization), che in Italia prende il nome di CP2011.
Alla CP2011 sono collegate numerose banche dati: le CO, l’indagine sulle professioni basata sul modello ONET, gli infortuni sul lavoro, gli sbocchi occupazionali dei corsi di laurea, l’indagine sulle forze lavoro, le retribuzioni e la riforma dei concorsi pubblici e dei piani di fabbisogno nel pubblico impiego. Per completare il panorama informativo, manca(va)no, oltre alla raccolta dei cv, l’analisi e la strutturazione e la rappresentazione dei dati relativi alle offerte di lavoro. Si tratta di un tassello essenziale, che consente di studiare un aspetto importante del mercato lavoro e di fornire dei cruscotti informativi utili ai cittadini, agli orientatori dei centri per l’impiego e ai decisori politici.
Raccogliere i dati relativi alle vacancies è un’operazione complessa: esistono numerosi motori di ricerca, alcuni con limitazioni riguardo al loro utilizzo, altri con API dedicate, alcuni dedicate alle aziende private, altri ai concorsi pubblici, ciascuno con criteri di ricerca diversi: il pericolo di trovare lo stesso dato replicato su diverse piattaforme è reale e introduce degli errori sistematici che influenzano negativamente le analisi. Inoltre, la strutturazione delle offerte di lavoro contenute in più dizionari eterogenei e diversificati introduce un ulteriore livello di complessità che, per non appesantire questo articolo, rimando a un approfondimento successivo. Basti sapere che per effettuare questa operazione è necessario l’impiego di un algoritmo in grado di individuare, ad esempio, l’offerta di lavoro denominata “SVILUPPATORE JAVA” e associarlo all’Unità Professionale, il massimo livello di dettaglio della CP2011, 3.1.2.1.0 — Tecnici programmatori.
Il sistema di raccolta utilizzato è basato su un crawler complesso, che consente l’interrogazione, la standardizzazione e l’archiviazione dei dati provenienti dalle piattaforme che pubblicano le offerte di lavoro e ne autorizzano l’utilizzo. Un’offerta di lavoro può essere rappresentata (e strutturata) abbastanza efficacemente, prendendo in considerazione il titolo, la descrizione, il luogo, l’azienda richiedente e il link al dettaglio e alla candidatura. Queste informazioni, collegate alla CP 2011, possono essere archiviate e analizzate agevolmente attraverso lo stack Elastic: un insieme di soluzioni basate sull’architettura REST, che consentono di lavorare con flussi di dati consistenti e monitorare il loro andamento componendo delle dashboard ad hoc. A questo punto c’è da chiedersi “Quanto sono big i dati riguardanti le offerte di lavoro?”. La risposta sincera sarebbe “poco”, ma è possibile articolare una risposta meno sincera… che dipende sostanzialmente da due fattori:
- le risorse a disposizione
- la frequenza di raccolta
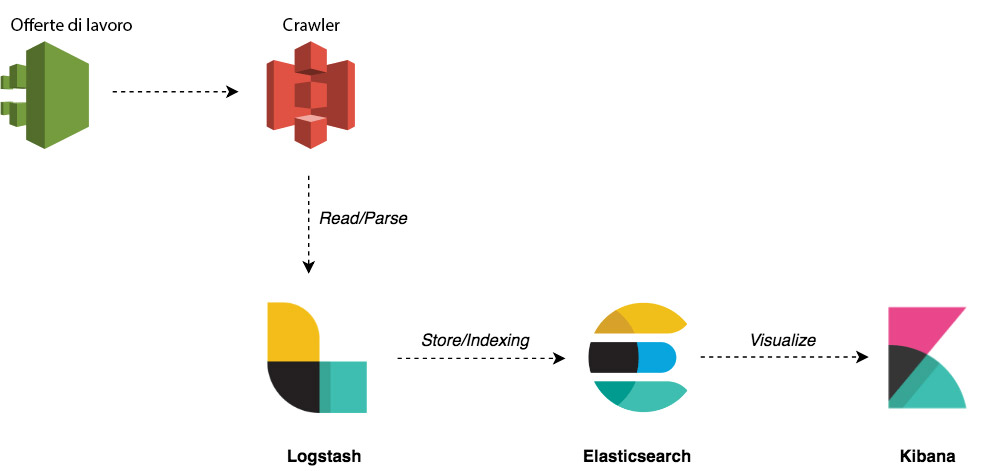
Un crawler ben strutturato, eliminando le duplicazioni, permette di acquisire circa 300.000 record giornalieri: tanti rispetto all’indagine statistica sulle forze lavoro, un’inezia rispetto ai tweet o al catalogo dei prodotti di Amazon. Poiché la frequenza con cui vengono aggiornate le vacancies non è molto elevata, avrebbe senso schedulare la raccolta compatibilmente con le reali necessità di analisi, allo scopo di ottimizzare ulteriormente la quantità di dati e di risorse impiegate. In entrambi i casi, è sufficiente un’architettura che contempli un nodo Elastic attraverso i suoi moduli Logstash, Elasticsearch e Kibana attraverso cui è possibile seguire il flusso logico schematizzato nella figura sottostante.
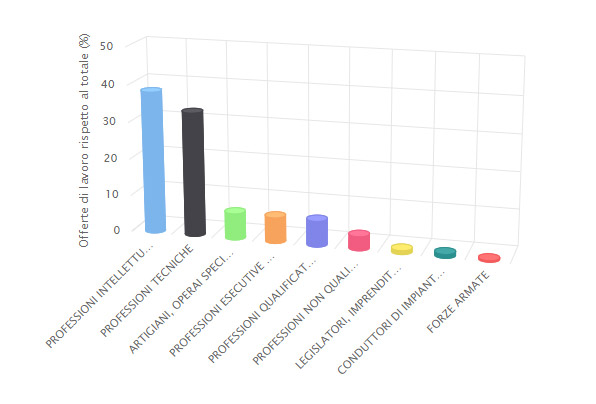
Tralasciando gli aspetti tecnologici, che meritano sicuramente approfondimenti ulteriori, è utile focalizzare l’attenzione sui risultati che si possono ottenere da un’analisi di questo tipo. In primo luogo, è possibile raggruppare i dati al massimo livello di aggregazione della CP2011 per capire quali sono le professioni più richieste all’interno di un singolo raggruppamento. Le professioni intellettuali e le professioni tecniche, al momento dell’analisi, rappresentano più del 70% dell’offerta.
Scendendo un po’ più nel dettaglio, e facendo un focus sulle professioni intellettuali, si può comprendere meglio la distribuzione degli annunci rispetto alle Unità Professionali contenute nel Grande Gruppo.
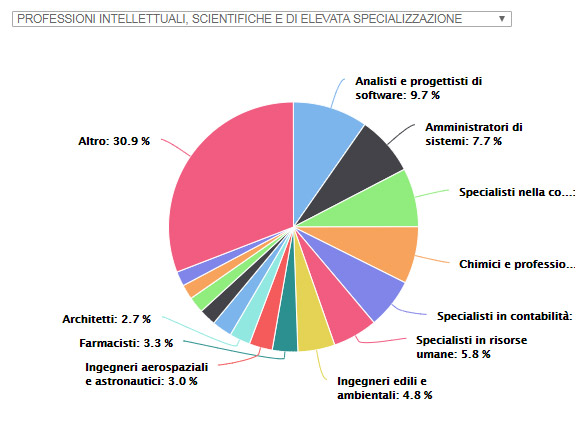
La rappresentazione grafica dei dati in un diagramma a torta è molto esplicativa: gli Analisti e progettisti di software, insieme agli amministratori di Sistemi, agli Specialisti nella commercializzazione di beni e servizi e ai Chimici, rappresentano circa il 20% dell’offerta complessiva.

I dati raccolti, disponibili per la consultazione sulla piattaforma http://www.iolavoro.info, permettono inoltre di fornire informazioni precipue e di analizzare nel dettaglio l’andamento in funzione delle Unità Professionali. Prendendo in esame l’Unità Professionale 2.1.1.1.1 — Fisici, si possono osservare diversi aspetti che non emergono dagli studi ufficiali condotti sul mercato del lavoro.In primo luogo, è possibile raggruppare le vacancies, per fornire un elenco completo e un panorama ampio integrato, grazie all’associazione con la CP2011, con le altre informazioni sulle professioni messe a disposizione dalle istituzioni (INAPP, INPS, UNIONCAMERE, MINISTERO DEL LAVORO, MIUR, Istat, Regioni).

Abbinando l’elenco delle offerte di lavoro all’elenco delle aziende e degli enti pubblici che pubblicano gli annunci, si possono comprendere i settori che esprimono un fabbisogno maggiore per una certa figura professionale. Nel caso in esame, l’Istituto di Fisica Nucleare, il Politecnico di Milano e L’Alma Mater Studiorum di Bologna sono gli enti pubblici a cui è associato il maggior numero di vacancies. Tra i soggetti privati, invece, spiccano le multinazionali che si occupano di ricerca e selezione di risorse umane (Ranstad, Orienta e Manpower).

La distribuzione territoriale è un altro indicatore importante per la valutazione dell’incidenza e del fabbisogno di una certa professione rispetto alle attività produttive e alle aziende dislocate sul territorio nazionale. Nel caso in esame, si può osservare una concentrazione elevata nel nord Italia e molto meno marcata al sud.
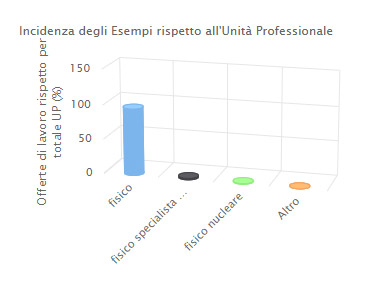
Tra gli esempi di professioni più rappresentativi c’è il Fisico, seguito dallo Specialista in fisica medica e dal Fisico nucleare. Questa differenziazione è più evidente se si prende in considerazione un’Unità Professionale diversa (es. Analisti e Progettisti di software) alla quale sono associati un maggior numero di voci elementari (analista di procedure, analista di programmi, analista programmatore, analista programmatore edp, bioinformatico, consulente per le applicazioni gestionali, consulente per le applicazioni informatiche industriali, ingegnere del software, progettista di sistemi vocali, sviluppatore software, capo progetto informatico, progettista di software, progettista sistemi multimediali, specialista progettista di prodotti di editoria elettronica).
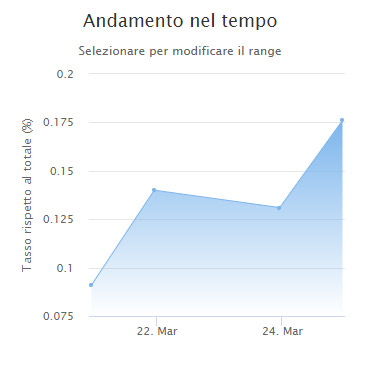
Un ulteriore strumento di grande rilevanza per numerose valutazioni è fornito dalla rappresentazione dell’andamento temporale. Conoscere il trend delle vacancies è importante per pianificare politiche e azioni mirate sui sistemi di istruzione, formando per tempo delle figure preparate e agendo con un livello di precisione rispetto al territorio molto elevato.
Ci sono numerosi altri aspetti che possono essere scandagliati attraverso la raccolta delle offerte di lavoro. Avendo accesso ai flussi delle CO e ai dati puntuali dell’indagine sulle forze lavoro, per esempio, si può comprendere meglio il rapporto tra l’offerta di lavoro e l’occupazione. Studiando i tempi di vita delle offerte lavorative, strutturate sulla base della CP2011, si può conoscere la velocità con cui una certa figura professionale viene inserita nel mercato del lavoro. Questa e altre questioni saranno illustrate in un paper dettagliato in corso di pubblicazione.